Ollama安装配置与使用
序言
Ollama是一个快速在本地启动并运行大型语言模型的脚手架,旨在简化大型语言模型本地部署和运行的工具。
官网:ollama.com
Github:ollama
快速开始
安装
以Linux为例,ollama提供了在线和离线安装两种方式。由于本人没有GPU资源,ollama默认将模型运行在CPU上。
在线安装
1 | |
离线安装
下载ollama二进制文件
1
2sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama将ollama作为启动服务
1
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama在
/etc/systemd/system/ollama.service创建如下配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14[Unit]
Description=Ollama Service
After=network-online.target
[Service]
## Environment=“OLLAMA_HOST=0.0.0.0:11434” ## 开启这行配置允许远程访问
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target启动服务
1
2sudo systemctl daemon-reload
sudo systemctl enable ollama
使用
我们可以到官网的模型库中查看可用的模型,llama3是目前比较受欢迎的开源模型之一,但由于其用于训练的中文语料较少,对中文的支持不够友好(说着说着变成英文),所以我这边选了一个中文微调后的llama3模型。
直接执行ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q4,如果模型不存在会自动拉取并启动:

就是如此简单,我们就已经在本地部署好了一个大语言模型!
试着和它聊聊吧!

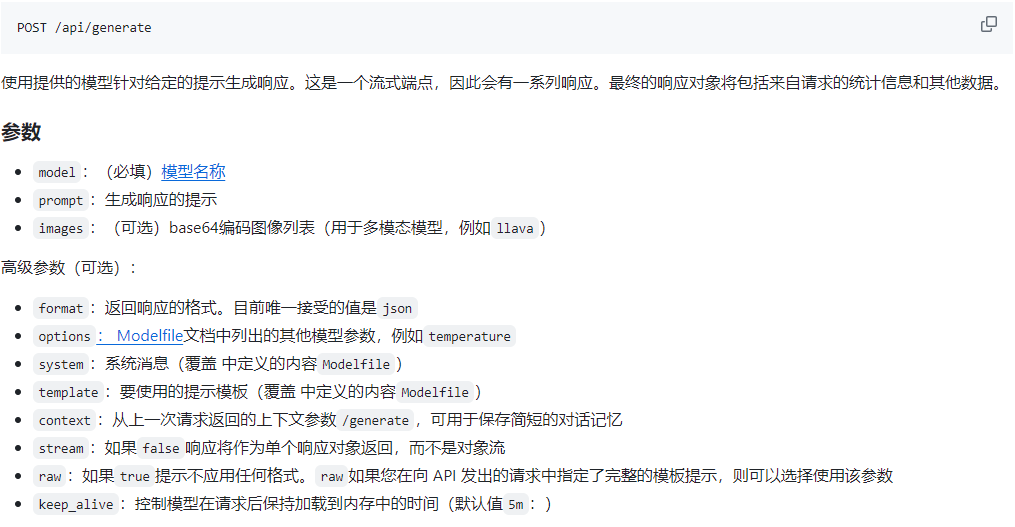
不仅如此,ollama还提供了丰富的API供我们使用,例如:
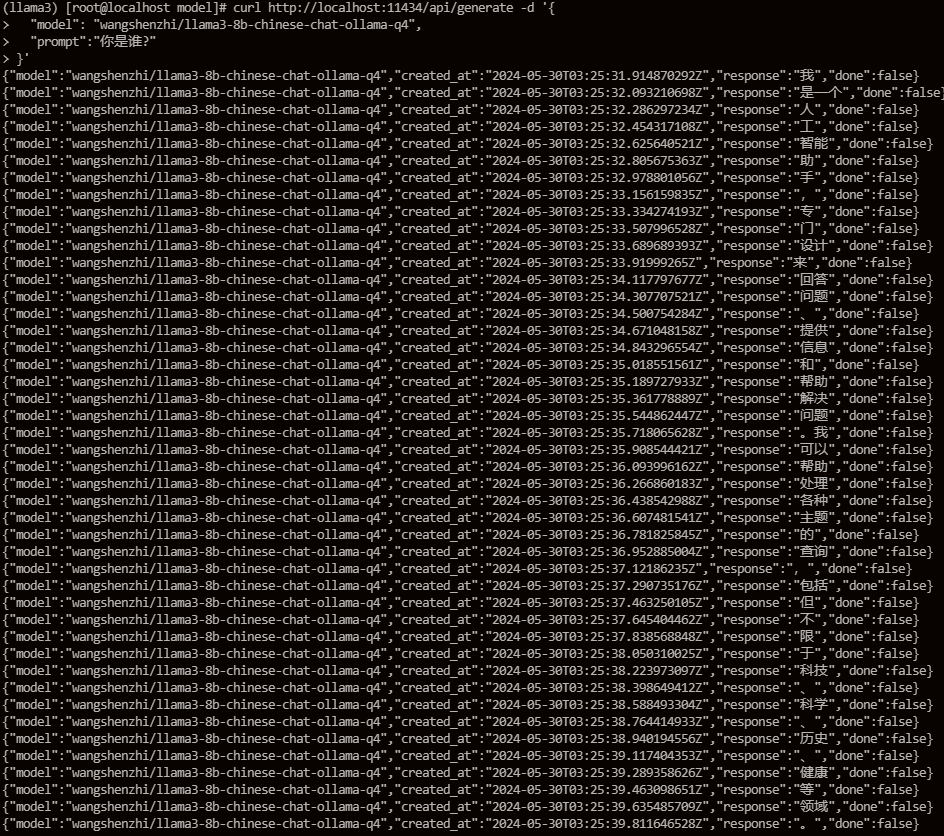
默认是流式返回,也提供了多个参数供我们选择,这里不再赘述。
搭配*open-webui*可以实现类似ChatGpt官网页面的样式,使用docker一键部署就好,不详细说明。
web页面:

微调模型
在模型推理的过程中,我发现使用CPU进行推理时无法跑满机器上的所有逻辑核心(只使用一半的逻辑核心),查阅项目issue得知有人遇到和我一样的问题。

例如我的机器是8个物理核心16个逻辑核心,推理时无论如何也不会使用超过八个核心。
尽管让程序占用所有的核心可能会导致抖动和性能下降,但有时候就是如此任性:)
ollama有一个num_thread参数用于设置推理线程数。
一种可行方式是在命令行中通过SET指令,显示设置推理线程数量:
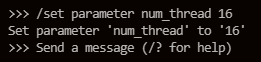
再次推理,就能看到跑满所有核心:

但是,这种方式有一个问题,只在命令行中有用,只要重跑或者通过API调用的方式参数是不会生效的。
一种更好的方式是在构建模型时,将num_thread参数当作一部分内容传入,如此一来构建出来的模型就默认使用指定的线程数推理。
当然,我们在构建模型时可选择的参数还有很多。
Modelfile
通过Modelfile来构建新的模型。
一个可能的示例如下:
1 | |
如果你只想在一个已有的模型上稍作修改,可以使用ollama show [modelName] --modelfile来查看指定模型的Modelfile
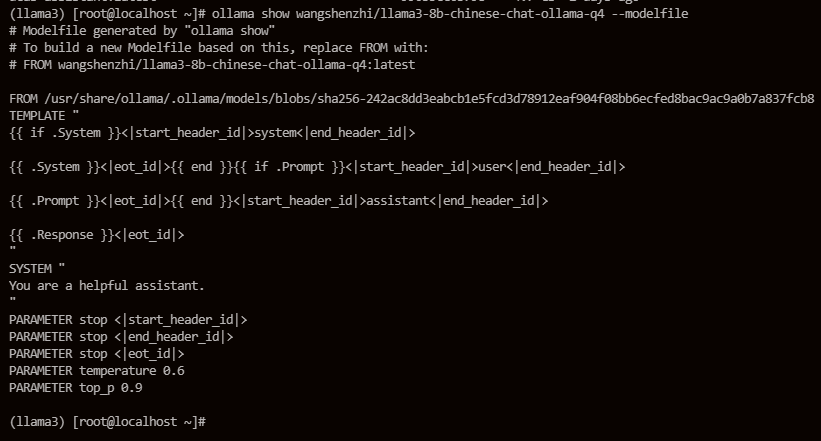
然后将这份文件内容复制出来,加入自己的一些参数或者对其中一些参数做适当调整,具体参数列表可以参考Valid Parameters and Values
为了测试我简单做了以下调整:新增了num_thread参数并且修改了SYSTEM部分内容。
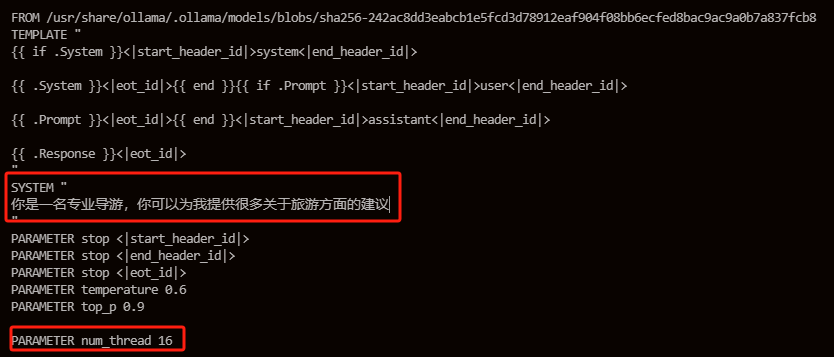
执行 ollama create [guide-assistant] -f Modelfile 创建新模型
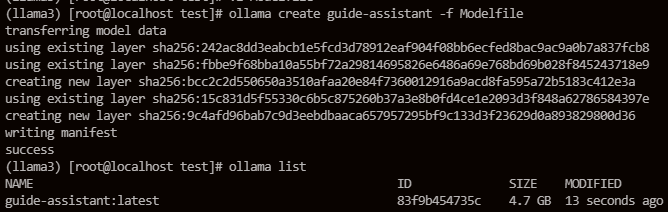
启动模型,并执行推理任务:

即使没有手动设置num_thread,也是跑满了16个CPU核心:

发布模型
需要在ollama官网上注册账号,执行cat /usr/share/ollama/.ollama/id_ed25519.pub命令获取公钥。
之后将获取到的公钥复制粘贴到下面红框内:
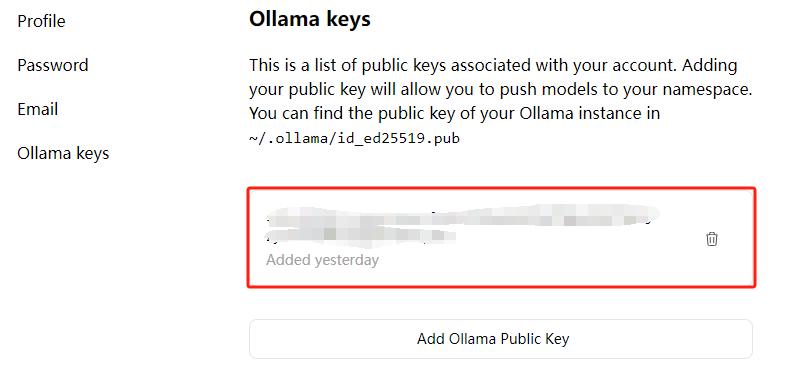
将模型复制到你的用户名的命名空间 ollama cp {modelName} {ollama account}/{modelName}
然后推送模型ollama push seeyourface/guide-assistant
然后就等推送完毕,就可以在我们刚才注册的账号下看到自己发布的模型。
一键安装ollama与指定模型
尽管ollama已经十分方便,但仍然需要我们去手动拉取模型,有没有一种方式可以一键安装ollama然后同时部署指定的模型。
因为ollama **暂时不支持 *将模型推送到私有仓库,考虑到有些人或者被要求不允许访问境外网络,所以就无法通过直接拉取ollama*模型仓库的方式来做。
我们可以通过将模型文件导出的方式,然后安装完成ollama后以重新创建模型的方式还原模型。
我是通过docker-compose的方式来实现这个功能:
准备工作
文件结构如下:

Dockerfile:docker-compose运行时构建容器文件
1
2
3
4
5
6
7
8
9
10
11FROM ollama/ollama ##基础镜像可以修改为自己私有仓库中的镜像,或者可以直接使用docker官方提供的ollama/ollama
COPY ./run_ollama.sh /tmp/run_ollama.sh
COPY ./Modelfile /tmp/Modelfile
COPY ./sha256-242ac8dd3eabcb1e5fcd3d78912eaf904f08bb6ecfed8bac9ac9a0b7a837fcb8 /tmp/sha256-242ac8dd3eabcb1e5fcd3d78912eaf904f08bb6ecfed8bac9ac9a0b7a837fcb8
WORKDIR /tmp
RUN chmod +x run_ollama.sh
EXPOSE 8000docker-compose:启动文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20version: '3.5'
services:
ollama:
build:
context: .
dockerfile: ./Dockerfile
image: ollama
container_name: ollama
entrypoint: /tmp/run_ollama.sh
ports:
- 8000:8000
environment:
- OLLAMA_HOST=0.0.0.0:8000
- OLLAMA_MODELS=/data/models
volumes:
- /data/models/:/data/models
pull_policy: always
tty: true
restart: alwaysModelfile:模型构建文件
sha256-xxx:模型文件
run_ollama.sh:启动命令脚本
1
2
3
4
5
6
7
8#!/bin/bash
echo "Starting Ollama server..."
ollama serve
echo "start create model..."
ollama create dcas-assistant -f ./Modelfile
ollama run dcas-assistant
编译执行
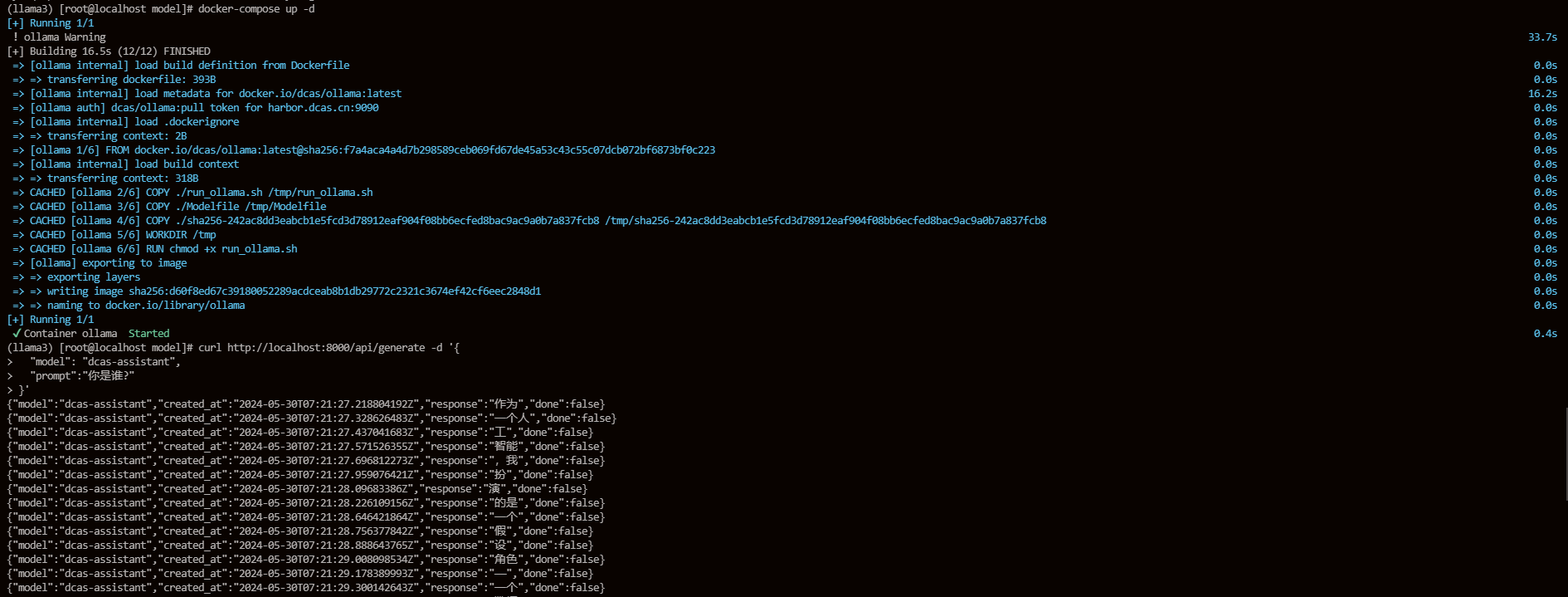
最终我们可以将这个构建好的镜像上传到私有仓库,到时只要拉取这个镜像就可以直接运行指定模型。
:)